Ryzen 5 7600X part 2: RAM details
To give some more advanced testing the time and effort it deserves while not delaying the info I’ve got any longer than necessary, I’m splitting this into several parts (part 1, part 2, part 3).
If you’re not sure what you’re doing, don’t try RAM overclocking (beyond XMP). In this case if all you do is enable XMP on a 5600+ kit, you’re already in pretty good shape, and RAM overclocking can and will make a fine mess of your system if you get it wrong.
If you want to tune just a few things, they should be fclk, tCL, tRCD, and tRFC. These deliver by far the best gains per your time spent tuning. A surprising number of other timings (tRRD_S is the worst) can hurt rather than help.
Infinity Fabric
Unfortunately there’s not as much room as there might be for RAM to matter, because the links between the cores and RAM don’t have as much bandwidth as the RAM itself. With AMD’s recommended tuned settings (2000 fclk and DDR5-6000), the RAM’s theoretical maximum is 96 GB/s, but the fabric’s theoretical maximum for reads is only 64 GB/s. On pure read workloads, at least it’s easy to get 57+ GB/s in practice.
I still can’t say much firsthand about writes and copies. I’m having trouble getting numbers that make sense, and it could well be a problem with my benchmarking (I’ve got reads nailed down but haven’t messed with writes and copies much before). There are a few things left to try.
As far as I know, all we have from AMD on this subject is a slide showing a dual-CCD package where each CCD gets 32B/cycle read bandwidth and 16B/cycle write bandwidth. If a lone CCD gets the same bandwidth as one of a pair, writes are going to be pretty slow.
However the details of that pan out, running the fabric (fclk) as fast as possible regardless of your RAM’s capabilities seems to be the way to go. With a single CCD there’s little way it could avoid being a major bottleneck, and practical testing agrees. With two CCDs things might be different.
Mitigating the lack of bandwidth somewhat, the L3 cache seems to make smart decisions about what it should and shouldn’t contain so that it’s of some use even on large bandwidth-bound working sets. I don’t know whether or not older AMD L3 caches do this. I’ve seen hints that recent Intel L3 caches do this too.
This sounds like a terrible mess to implement, but just in case, I checked to see if fabric traffic is compressed at all. It’s not. Zeroes don’t go any faster than random data. (Even very simple compression would make limited fabric bandwidth make perfect sense.)
RAM selection
Due to the bandwidth situation, it’s not worth putting any significant money into RAM that clocks higher (at least for single-CCD CPUs). Timings do matter though. In the current state of the market, one of the cheaper kits using Samsung dies like the one I bought still seems like the way to go after going through the tuning details, but one of the cheaper Hynix-based kits like this or this might deliver some noticeable gains via lower tRFC.
Latency and random throughput
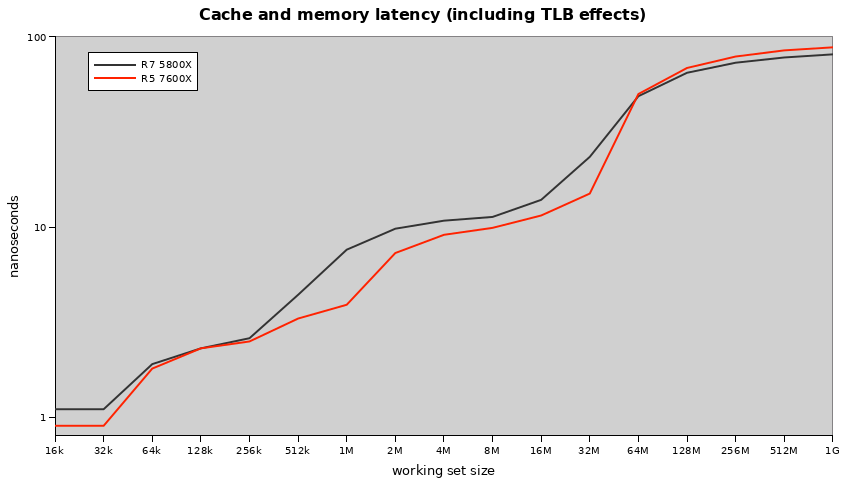
Zen 4’s higher clocks do wonders for its effective latencies. Between the larger L2 cache and effectively snappier L3 cache, it gets large wins across a wide range of working set sizes. When it has to go all the way out to RAM it falls behind (the gap is about 7 nanoseconds with these setups and there’s much more room for more expensive and better-tuned RAM to help out the 5800X than the 7600X).
Random throughput to memory has always been a bit of a fuzzy metric to try to do any actual comparisons with, and in this case it’s so high it’s barely meaningful. In some cases it does over 800 MT/s. If everything works as a 64B cache line end-to-end, this is over 51 GB/s at the memory, approaching the fabric’s read bandwidth limit despite the random access pattern! DDR5 was designed with this in mind and it delivers.
Clock limits
I haven’t fiddled with voltages much yet. That’s probably for part 4. At the default 1.20 Vsoc, fclk tops out for me at 2066. I haven’t got my Samsung-based (5S16B) RAM to go beyond 6200 (yet?), which is too low to tell anything about uclk.
ODECC (On-Die Error Correction Codes)
Unfortunately, I can’t tell that there’s any reporting of ODECC corrections whatsoever. It’s possible they just show up in a weird place I didn’t consider, though. It’s no surprise that they’re missing, but it is disappointing: RAM is one of the less reliable components of a computer, it’s particularly good at wreaking havoc when it fails, and this is a missed opportunity for some better diagnostics. Having some report of RAM’s internally corrected errors could save people a lot of debugging time.
RAM tuning results
All of the tuning below was done with the RAM at 1.35V, the highest common default for Samsung-based kits.
Here are the timings used all in one place:
| timing | 6k auto | minimum | final |
|---|---|---|---|
| tCL | 40 | 36 | 36 |
| tRCD | 40 | 34 | 34 |
| tRP | 40 | 34 | 34 |
| tRAS | 80 | 66 | 66 |
| tRC | 120 | 100 | 100 |
| tWR | 90 | 48 | 48 |
| tRFC | 884 | 820 | 820 |
| tRTP | 23 | 10 | 10 |
| tRRD_L | 15 | 6 | 14 |
| tRRD_S | 8 | 4 | 6 |
| tFAW | 32 | 20 | 24 |
| tWTR_L | 30 | 18 | 20 |
| tWTR_S | 8 | 4 | 6 |
| TrdrdScL | 8 | 4 | 6 |
| TrdrdSd | 8 | 1 | 2 |
| TrdrdDd | 8 | 1 | 2 |
| TwrwrScL | 23 | 4 | 6 |
| TwrwrSd | 15 | 7 | 8 |
| TwrwrDd | 15 | 7 | 8 |
| Twrrd | 8 | 2 | 4 |
| Trdwr | 21 | 14 | 16 |
The only non-auto settings in the auto column are the 40-40-40-80-120. There are very few circumstances where you’d ever run a looser set of primaries than that (with the exception of tRC, which in retrospect I probably should have left auto here).
The minimum column is mostly either the minimum stable values or the minimum values it’s possible to set. I didn’t look for one-clock granularity on most things, tRAS could probably drop a couple points (I hadn’t figured out its behavior yet on the main pass through these), tRRD_L stays higher than tRRD_S to prioritize different bank groups when possible, I didn’t check TwrwrSd and TwrwrDd separately, and tRFC’s actual minimum in stability tests is 780 but pushing tRFC hard is a bad idea if you value a bitrot-free system.
The final column is about improving performance over the minimums, not about stability (I 24/7 5800 instead of 6000 to put stability margin on all of the timings). I’m sure it’s possible to do better than this with more tuning time, but this should at least be very close.
I tested performance using static scenes in Deep Rock Galactic, Warhammer: Vermintide 2, and Planetside 2, all of which I have some experience getting repeatable numbers out of. All three scenes have roughly 3 fps of natural variance in this case, so a lot of these differences are still a bit fuzzy. Vermintide 2 and Planetside 2 don’t have repeatable enough 1% lows to be worth looking at. I still think this is far more valuable data than I could get with more repeatable but more synthetic workloads.
I started testing at 1733 fclk, 5200 MT/s RAM, and 34-34-34-68-102, and sped things up in small batches from there.
Here are the full performance results in the order I tested them:
| config changes | DRG avg | DRG 1%low | V2 avg | PS2 avg |
|---|---|---|---|---|
| initial 1733:5200CL34 | 251 | 195 | 167 | 221 |
| fclk 2000 | 252 | 216 | 182 | 223 |
| 6000CL40 autos | 252 | 220 | 183 | 224 |
| CL 36, RCD 34 | 263 | 223 | 188 | 236 |
| rdrdScL 4, wrwrScL 4 | 260 | 225 | 188 | 239 |
| RRD_S 4, RRD_L 6, FAW 20 | 257 | 218 | 176 | 227 |
| RP 34, RAS 66, RC 100, WR 48, RTP 10 | 258 | 224 | 188 | 233 |
| WTR_S 4, WTR_L 18, wrrd 2, rdwr 14 | 254 | 223 | 189 | 233 |
| RFC 820 | 264 | 229 | 190 | 239 |
| rdrdSd/Dd 1, wrwrSd/Dd 7 | 267 | 231 | 187 | 234 |
| RRD_L 14 | 265 | 229 | 194 | 238 |
| FAW 32 | 260 | 222 | 189 | 235 |
| RRD_S 8 | 271 | 230 | 183 | 241 |
| RRD_S 6, FAW 24 | 268 | 227 | 188 | 244 |
| RRD_L 8 | 260 | 227 | 189 | 241 |
| RRD_L 14, WTR_S 6, WTR_L 20, wrrd 4, rdwr 16 | 264 | 229 | 192 | 250 |
| rdrd/wrwrScL 6, rdrdSd/Dd 2, wrwrSd/Dd 8 | 265 | 232 | 193 | - |
The last PS2 datapoint is missing because the scene can only be tested at certain times of day due to its multiplayer nature, the testing took too long and I could no longer get solid results, and when I came back to it there had been a game update so numbers can no longer be directly comparable.
The rest of this is commentary on each tuning step.
fclk 2000
DRG 1% lows and Vermintide averages see great gains from speeding up the infinity fabric. With gains like these, it’s tough to see any reason to run it below 2000, and it’s worth seeing just how fast it can go if you’re tweaking anything at all.
6000CL40 autos
This brings the timings to those in the 6k auto column further up, which are similar when measured in nanoseconds. Boosting the memory frequency doesn’t seem to be worth much, and at least on single-CCD CPUs it’s not worth any serious tuning time. It only has to be early in the process since everything else depends on it.
CL 36, RCD 34
These have the biggest impact on memory latency: if you need a small piece of data from RAM and the RAM is otherwise idle, these two are the timings you have to wait on to get that data. Since this hardware is naturally weak at latency, strong at random throughput, and limited elsewhere at bandwidth, it makes sense that these two timings would be disproportionately important, and the performance results confirm that.
rdrdScL 4, wrwrScL 4
These are a big deal for practical bandwidth on DDR4, but don’t do much here, despite the defaults being very loose. This might just be because bandwidth is that thoroughly bound by fclk instead.
RRD_S 4, RRD_L 6, FAW 20
These limit how quickly rows can be opened. This was a go-to change on DDR4, but unintuitively here, cinching these down without supporting changes damages performance badly rather than helping it. With the supporting changes, it’s still a mixed bag, with different games preferring different settings (and none of them preferring the minimum settings). The supporting settings needed to make this work at all have to do with how soon rows can be closed, so presumably the problem is something to do with too many rows needing to be closed all at once and relaxing these three timings spreads that work out better.
A possible alternative explanation is that opening rows is very power-hungry and opening too many rows too quickly causes other problems via voltage droop. I don’t think this is it, because all of these three can go extremely low without any actual errors while all other timings are at their stability limits and because increasing tFAW in particular (which is all about limiting power spikes) makes things worse instead of better. Instead, raising the RRDs is key, and tFAW should always be at its minimum of four times tRRD_S.
RP 34, RAS 66, RC 100, WR 48, RTP 10
These have to do with closing rows, and are needed to support any cinching of tRRD_S, tRRD_L, and tFAW. Cinching these mostly but not entirely undoes the damage from the last step. (These don’t give such large gains in the absence of RRD tweaks.)
tRAS and tRC have important interactions.
WTR_S 4, WTR_L 18, wrrd 2, rdwr 14
These should make mixed reads and writes go faster, but make things possibly worse rather than better.
RFC 820
Despite DDR5’s nicer refresh behavior, this still delivers a large improvement by reducing the amount of time the RAM spends refreshing instead of available to access. These Samsung dies don’t have a whole lot of room to tighten tRFC, and the available gains should be much larger on Hynix M-die. Low tRFCs are particularly good at creating subtle bitrot problems, so be careful with this one and probably leave some extra margin.
rdrdSd/Dd 1, wrwrSd/Dd 7
My understanding of these is that they shouldn’t matter in this case since there’s only one rank of RAM, but that’s clearly not right, because they do affect stability. Their performance effects are ambiguously bad.
RRD_L 14
With all timings cinched, it’s time to go back and see what tRRD_S, tRRD_L, and tFAW are ideal, since it’s clearly not the minimums. Higher tRRD_L looks like a net win from this step, but also not the kind of improvement we’re really looking for.
FAW 32
tFAW isn’t the problem. It should always stay at its minimum of four times tRRD_S.
RRD_S 8
Vermintide doesn’t appreciate this, but everything else does.
RRD_S 6, FAW 24
Vermintide and DRG are both mostly fine with this one and it’s the best result yet for PS2. This seems like the way to go, at least for these three scenes.
RRD_L 8
The ideal tRRD_L might change based on tRRD_S. Dropping tRRD_L back to 8 isn’t a net win though, and smaller changes would probably get lost in the noise.
RRD_L 14, WTR_S 6, WTR_L 20, wrrd 4, rdwr 16
With tRRD_L back up to 14, it’s time to revisit the other timings that produced dubious gains. Adding 2 to everything in this batch seems to be a net win.
rdrd/wrwrScL 6, rdrdSd/Dd 2, wrwrSd/Dd 8
Bringing the other set of dubious timings up a bit also looks like it probably at least doesn’t hurt.
It’s possible to figure out plenty of detail beyond this, but this is very time-consuming testing and this is already a lot of data to work with, so this is where I called it for now.
I don’t have a good sense of why so many timings wouldn’t appreciate being minimized, but clearly minimizing everything isn’t the best play here. Fortunately, most of the available gains are concentrated in just a few better-behaved timings, and it’s safe to ignore the rest.